Abstract
Learning dense visual representations without labels is an arduous task and more so from scene-centric data. We propose to tackle this challenging problem by proposing a Cross-view consistency objective with an Online Clustering mechanism (CrOC) to discover and segment the semantics of the views. In the absence of hand-crafted priors, the resulting method is more generalizable and does not require a cumbersome pre-processing step. More importantly, the clustering algorithm conjointly operates on the features of both views, thereby elegantly bypassing the issue of content not represented in both views and the ambiguous matching of objects from one crop to the other. We demonstrate excellent performance on linear and unsupervised segmentation transfer tasks on various datasets and similarly for video object segmentation.
CrOC Overview
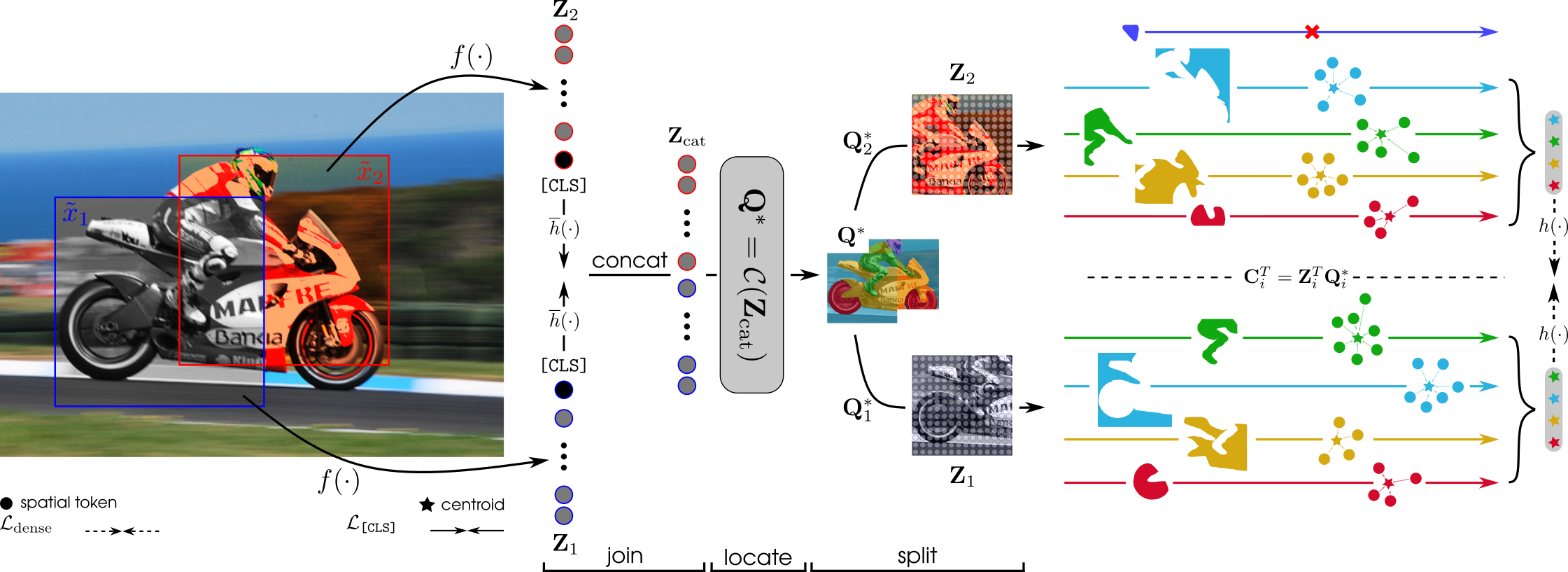
Below, we illustrate an overview of the CrOC training pipeline for learning dense visual representations from unlabeled scene-centric data.
We introduce a novel paradigm dubbed join-locate-split:
Join. The two augmented image views, x̃1 and x̃2, are processed by a ViT encoder f yielding the dense visual representations Z{1, 2} ∈ ℝN × d, where N and d denote the number of spatial tokens and feature dimension, respectively.
The dense visual representations are then concatenated along the token axis to obtain the joint representation, Zcat ∈ ℝ2N × d.
Locate. The objective is to find semantically coherent clusters of tokens in the joint representation space. As the quality of the input representation improves, we expect the found clusters to represent the different objects or object parts illustrated in the image. The joint representation is fed to the clustering algorithm 𝒞, which outputs the joint clustering assignments, Q* ∈ ℝ2N × K. The soft assignments matrix Q* models the probability of each of the 2N tokens to belong to one of the K clusters found in the joint space.
Split. By splitting Q* in two along the first dimension, the assignment matrix of each view, namely Q{1, 2}* ∈ ℝN × K are obtained. One can observe that the link operation is provided for free and that it is trivial to discard any cluster that does not span across the two views.
Given the view-wise assignments Q{1, 2}*, and the corresponding dense representations Z{1, 2}, K object/cluster-level representations can be obtained for each view as: C1⊤ = Z1⊤Q1*, where
C denotes the centroids. Analogously to the image-level consistency objective, one can enforce similarity constraints between pairs of centroids.
 |
|
CrOC Results
We opt for dense evaluation downstream tasks, which require as little manual intervention as possible, such that the reported results truly reflect the quality of the features. The main tasks include:
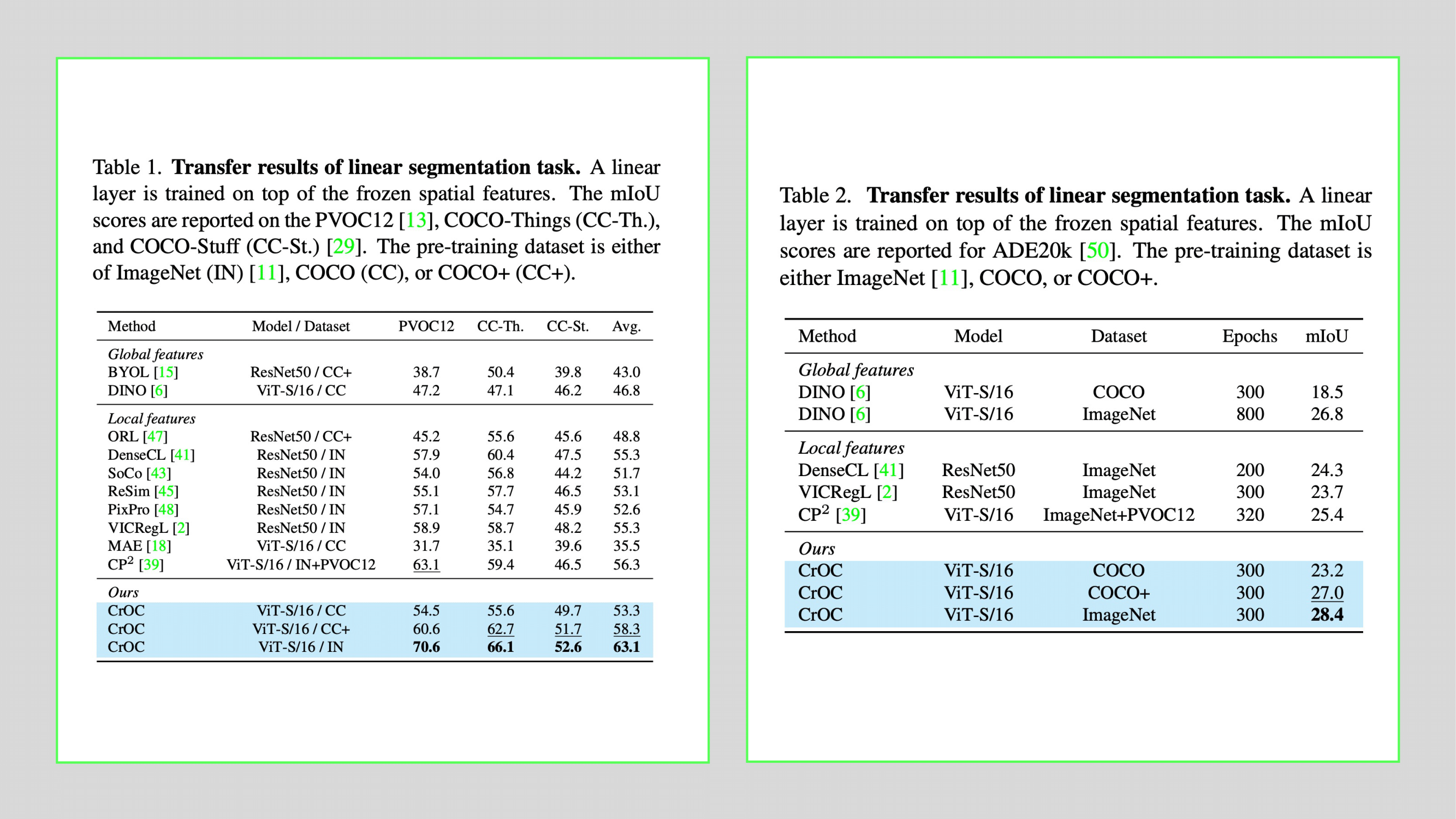
Transfer learning via linear segmentation. The linear separability of the learned spatial features is evaluated by training a linear layer on top of the frozen features of the pre-trained encoder. We report the mean Intersection over Union (mIoU) of the resulting segmentation maps on three different datasets, namely PVOC12, COCO-Things (CC-Th.), and COCO-Stuff (CC-St.). The pre-training dataset is either ImageNet (IN), COCO (CC), or COCO+ (CC+).
Transfer learning via unsupervised segmentation. We evaluate the ability of the methods to produce spatial features that can be grouped into coherent clusters. We perform K-Means clustering on the spatial features of every image in a given dataset with as many centroids as there are classes in the dataset. Subsequently, a label is assigned to each cluster via Hungarian matching. We report the mean Intersection over Union (mIoU) of the resulting segmentation maps on three datasets, namely PVOC12, COCO-Things (CC-Th.), and COCO-Stuff (CC-St.).
Below, we show comparison results with respect to SOTA methods:
 |
|
Try our code
We released PyTorch code and models of the CrOC for your use.
Paper
 |
T. Stegmüller, T. Lebailly, B. Bozorgtabar, T. Tuytelaars, J.P. Thiran
CrOC: Cross-View Online Clustering for Dense Visual Representation Learning.
In CVPR, 2023.
ArXiv
|
BibTeX
@inproceedings{Stegmüller2023CrOC,
title={CrOC: Cross-View Online Clustering for Dense Visual Representation Learning},
author={Stegmüller, Thomas and Lebailly, Tim and Bozorgtabar, Behzad and Tuytelaars, Tinne and Thiran, Jean-Philippe},
booktitle={Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR)},
year={2023}
}
Acknowledgements
We thank Taesung Park for his project page template.
|

