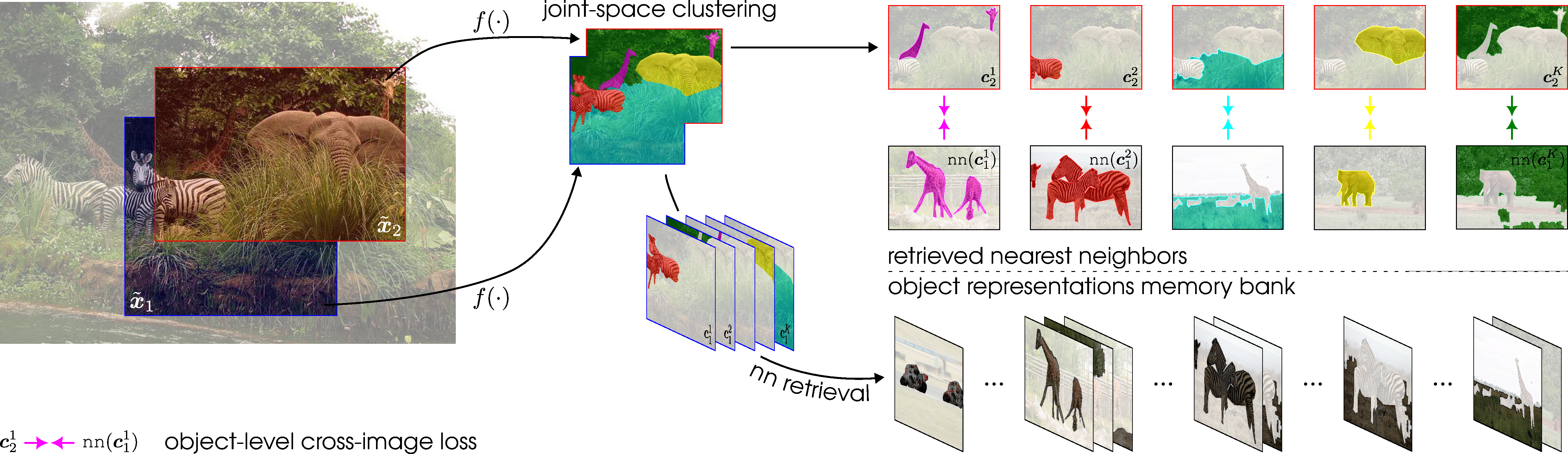
1. Semantically Coherent Image Regions
The first step towards cross-image object-level bootstrapping is to identify semantically coherent image regions within the images. To that end, we rely on an online joint-space clustering algorithm from [Stegmuller_2023_CVPR].
Joint-space clustering.
The clustering algorithm takes as input the dense representations \( \mathbf{z}_1 \in \mathbb{R}^{N \times d} \) and \( \mathbf{z}_2 \in \mathbb{R}^{N \times d} \) associated with the two augmented views and concatenates them along the token axis to obtain the dense representation of the joint-view, \( \mathbf{z}_{\text{cat}} \in \mathbb{R}^{2N \times d} \). The \( 2N \) tokens are subsequently partitioned into \( K \) clusters to produce semantically coherent and spatially compact clusters. A hyperparameter \( \lambda_{\text{pos}} \) modulates the importance of the spatiality against that of the semantic. The resulting assignment is encoded in a matrix \( \mathbf{Q}^{*} \in \mathbb{R}^{2N \times K} \), which can be split in two to obtain the view-wise assignments \( \mathbf{Q}^{*}_1, \mathbf{Q}^{*}_2 \in \mathbb{R}^{N \times K} \). Here \( \mathbf{Q}^{*}_i(n,k) \) denotes a soft-assignment of token \( n \) to object-cluster \( k \) in view \( i \). These can in turn be used to compute the \( K \) object representations \( \mathbf{c}_i \in \mathbb{R}^{d} \) in each view \( i \) as follows:
\[ \mathbf{c}_i^k = \sum_{n \in [N]} \mathbf{Q}^{*}_i(n,k) \cdot \mathbf{z}_i^n,\quad i \in \{1,2\} \]
Note that the columns of \( \mathbf{Q}^{*}_i \) undergo \( l_1 \) normalization, rendering the object representations as affine combinations of local representations. observed that the cross-view correspondence is provided for free as the object representation \( \mathbf{c}_1^k \) from the first view is matched to \( \mathbf{c}_2^k \) in the second one as a consequence of the joint-space clustering. In practice, it can be the case that some objects are exclusive to one of the two views, i.e., \( \sum_{n \in [N]} \mathbf{Q}^{*}_i(n,k) = 0 \). In that case, the object \( k \) is simply discarded from the view where it is present.
3. Self-Supervised Training Objectives
CrIBo’s final training objective involves three distinct types of self-supervision: cross-view object-level, cross-image object-level, and global cross-image. All levels of self-supervision are based on the self-distillation mechanism, which employs a student-teacher pair of siamese networks \(f_s\) and \(f_t\), respectively. Given two augmented views \(\tilde{\boldsymbol{x}}_1\) and \(\tilde{\boldsymbol{x}}_2\), global representations and object representations can be obtained for each view and each network within the siamese pair.
Cross-View Object-Level Self-Supervision
The object representations from the teacher and student are fed to their respective head \(h_s\) and \(h_t\) to output probability mass functions whose sharpness can be modulated via temperature parameters (\(\tau_{s}\) and \(\tau_{t}\)). For the teacher, this translates to:
\[
\mathbf{p}_{i,t}^k = \texttt{softmax}\left(\text{head}_{t}(\mathbf{c}_{i,t}^k) / \tau_{t} \right), \quad i \in \{1,2\}
\]
The student's projections are obtained analogously. The cross-view object-level loss is expressed as the averaged cross-entropy over all pairs of object representations and making the loss symmetric with respect to the student/teacher:
\[
\mathcal{L}_{cv}^{o} = \frac{1}{K}\sum_{k \in [K]} \left( H(\mathbf{p}_{1,t}^k, \mathbf{p}_{2,s}^k) + H(\mathbf{p}_{2,t}^k, \mathbf{p}_{1,s}^k) \right)
\]
where \(H(\mathbf{a}, \mathbf{b}) = -\sum_{l=1}^{L} \mathbf{a}_{l} \log (\mathbf{b}_{l})\) denotes the cross-entropy.
Cross-Image Object-Level Self-Supervision
Once all object representations in the batch have been retrieved, the cross-image object-level loss is enforced in a manner analogous to its cross-view counterpart. The nearest neighbors are first fed to the projection head as follows:
\[
\tilde{\mathbf{p}}_{i,t}^{k} = \texttt{softmax}\left(h_{t}(\texttt{nn}(\mathbf{c}_{i,t}^k)) / \tau_{t} \right), \quad i \in \{1,2\}
\]
Note that these projections are only defined for the teacher since the \(\texttt{nn}(\cdot)\) operator is not differentiable. The formulation of the cross-image object-level loss aligns with that in the cross-view loss up to the filtering of invalid positive pairs:
\[
\mathcal{L}_{ci}^{o} = \frac{1}{Z_1}\sum_{k \in [K]} \mathbb{1}_{\{\mathcal{O}(\mathbf{c}_1^k)\}} H(\tilde{p}_{1,t}^{k}, p_{2,s}) + \frac{1}{Z_2}\sum_{k \in [K]} \mathbb{1}_{\{\mathcal{O}(\mathbf{c}_2^k)\}} H(\tilde{p}_{2,t}^{k}, p_{1,s})
\]
where \( \mathbb{1}_{\{\cdot\}} \) denotes the indicator function and where \( Z_1 \) and \( Z_2 \) are normalization constants, i.e., \( \sum_{k \in [K]} \mathbb{1}_{\{\mathcal{O}(\mathbf{c}_1^k)\}} \) and \( \sum_{k \in [K]} \mathbb{1}_{\{\mathcal{O}(\mathbf{c}_2^k)\}} \), respectively.
Global Cross-View Self-Supervision
Importantly, both the clustering and the bootstrapping steps are contingent on the quality of the representations. To avoid potential instabilities, we incorporate a global cross-view loss into our framework, offering meaningful self-supervision at any stage of the pretraining. This loss is analogous to the one from the cross-view object-level loss except that it is applied to the global representation (\(\mathbf{z}_{1,s}\), \(\mathbf{z}_{2,s}\), \(\mathbf{z}_{1,t}\), and \(\mathbf{z}_{2,t}\)), which are fed to a dedicated head \( \overline{h} \):
The global cross-view projections are defined as follows:
\[
\overline{p}_{i,t} = \texttt{softmax} \left(\overline{h}_{t}(\mathbf{z}_{i,t}) / \overline{\tau}_{t}\right), \quad i \in \{1,2\}
\]
where \(\overline{\tau}_{s}\) and \(\overline{\tau}_{t}\) are the corresponding temperature parameters for the \(\overline{L}\)-dimensional output distribution. The global cross-view loss is defined as:
\[
\mathcal{L}_{cv}^{g} = H(\overline{p}_{1,t}, \overline{p}_{2,s}) + H(\overline{p}_{2,t}, \overline{p}_{1,s})
\]
where \(H(\mathbf{a}, \mathbf{b}) = -\sum_{l=1}^{\overline{L}} \mathbf{a}_{l} \log (\mathbf{b}_{l})\).
Finally, we obtain the overall training objective of CrIBo as a sum of its individual components:
\[
\mathcal{L}_{\text{tot}} = \mathcal{L}_{cv}^{g} + \mathcal{L}_{cv}^{o} + \mathcal{L}_{ci}^{o}
\]
The student's parameters are optimized to minimize the above loss whereas the parameters of the teacher are updated via an exponential moving average of the student's weights.
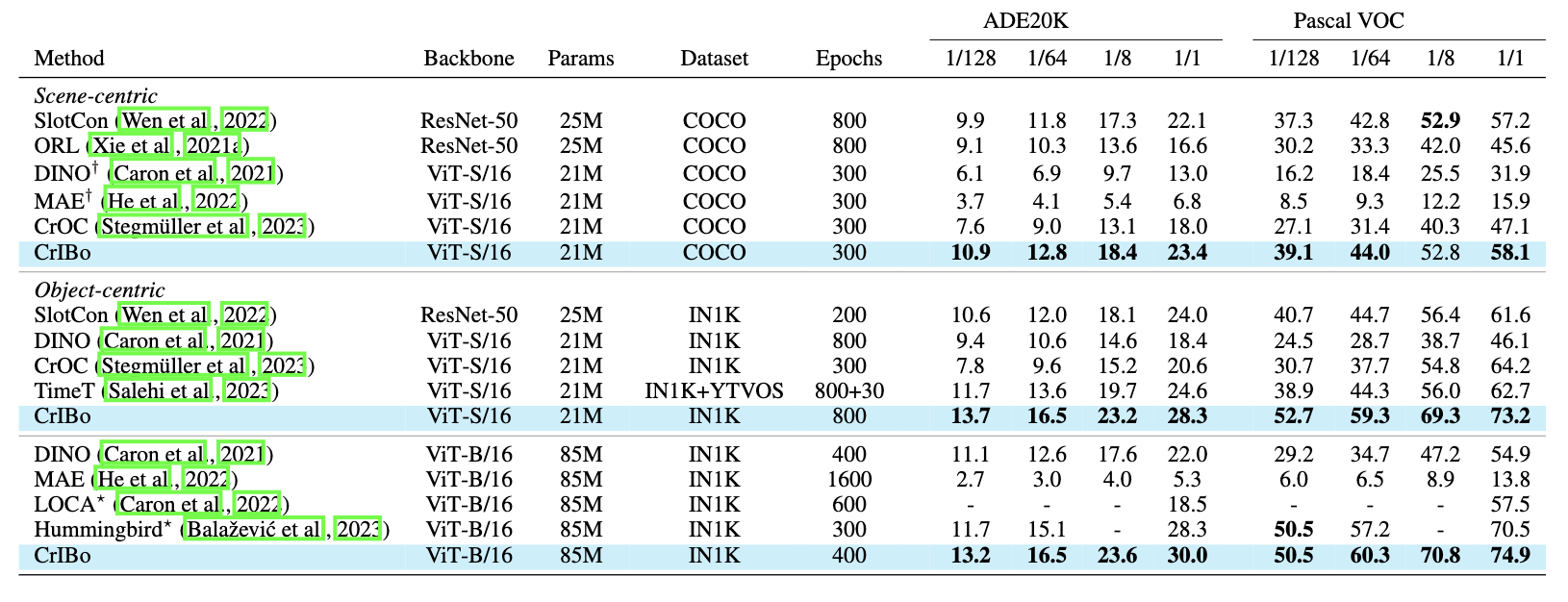
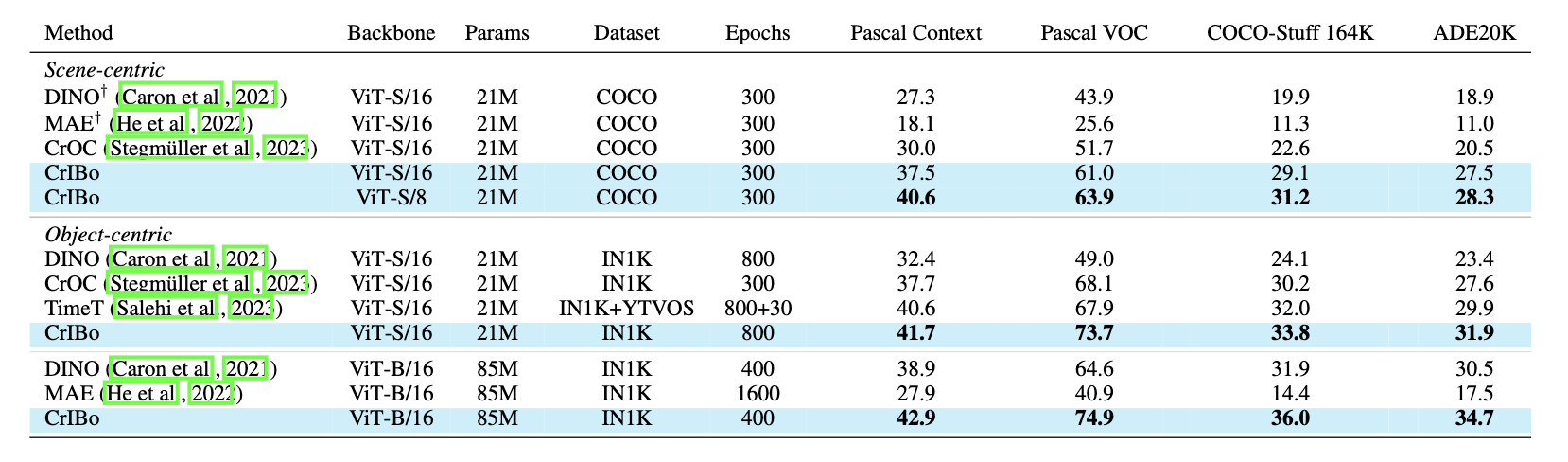
 : Self-Supervised Learning via Cross-Image Object-Level Bootstrapping
: Self-Supervised Learning via Cross-Image Object-Level Bootstrapping